
ローカル版DifyにOllamaを登録する
Contents
ローカルPCのDocker版Difyに、Ollamaを登録する方法を記述します。
この記事の前提となる構成は以下です。
-
Dify:ローカルPC上の Docker Desktop で起動
-
Ollama:同じローカルPCで起動
-
使ったモデル:
llama3.1:8b, nomic-embed-text
結論
- 同じPC上でも、DifyがDockerコンテナで動いている場合は、Difyから見た
localhostは コンテナ自身を指す - そのため、OllamaのURLに
localhostを入れると失敗する
正しい考え方
-
Dify(Docker) → ホストOS上のOllama に繋ぐときは
✅http://host.docker.internal:<ポート>を使う
準備
Dify起動
docker-compose.yml があるフォルダ(例:c:\docker\dify_2026_02\dify\docker)に移動して、以下を実行します。
- cd c:\docker\dify_2026_02\dify\docker
- docker compose up –d
以下のコマンドで状態を確認します。Upと表示されていれば動いています。
- docker compose ps
ブラウザーで、http://localhost/にアクセスし、Difyにログインします。
- http://localhost
- Difyにログイン
Ollama起動
Windows PowerShellを新たに起動し、以下のコマンドを実行します。
- ollama serve
- ポート番号:11434 → 12000
LLMモデル確認
- ollama list
表示されたLLMモデルをメモしておきます。
私の環境では、llama3.1:8bが入っていることを確認しました。
- llama3.1:8b
LLMモデルは、各自が動かしたLLMモデルです。
Difyにモデルプロバイダーをインストール
モデルプロバイダーをインストール
モデルプロバイダーの設定画面にいきます。
- Dify → 設定 → モデルプロバイダー
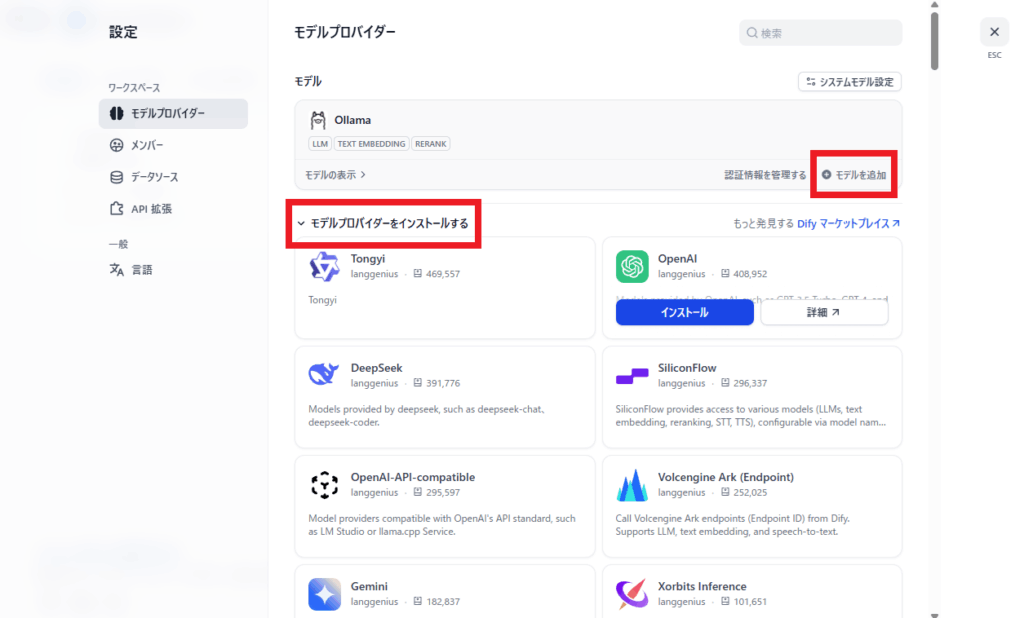
項目「モデルプロバイダーをインストールする」にOllamaがあるので「インストール」をクリックします。
- モデルプロバイダーをインストールする → Ollama → 「インストール」
「インストール」とありますが、LLMモデルを再度インストールするのではなく、プロバイダー情報を設定するといった意味です。
「設定中」と表示されていても正常です。
LLMモデルの設定
「APIキーを設定するか、使用するモデルを追加してください」とでることがあります。
そうしたら、OllamaはAPIキー不要なので 「モデルを追加」 をクリックします(画像1参照)。
- 「モデルを追加」をクリック
設定画面になるので、LLMモデルを設定します。
-
Model Type:
LLM -
Completion mode:
Chat -
Vision support:
No -
Function call support:
No(まずは) -
Base URL / Server URL:
http://host.docker.internal:12000 -
Model name:
llama3.1:8b -
認証名(任意):例
ollama-local-12000
各設定の意味
- Completion mode
Chat:会話アプリ向け(基本はこちら)Completion:単発補完系(迷ったら使わない)
- Vision support
llama3.1:8bは通常画像入力モデルではないのでNo
- Function call support
- 初期段階では
Noが安定(あとで必要ならON)
- 初期段階では
「Base URL / Server URL」は、ポート番号を記述します。ポート番号が12000であれば、以下となります。
- http://host.docker.internal:12000
「Model name」は、Ollamaで動かしているLLMモデルを記述します。
- Ollama3.1:8b
「認証名」は 秘密情報ではなくラベル名です。空欄でもよいことが多いですが、複数設定したときに分かりづらくなるため、入れておくのがおすすめです。
- 以下、おすすめ例
ollama-local-12000win-ollama-12000
「システムモデルが未設定」の警告が出た場合
Difyでモデル追加後に、次のような警告が出ることがあります。
- システムモデルがまだ完全に設定されておらず、一部の機能が利用できない場合があります
これは、Dify全体で使うデフォルトモデル(システムモデル)が未設定という意味です。
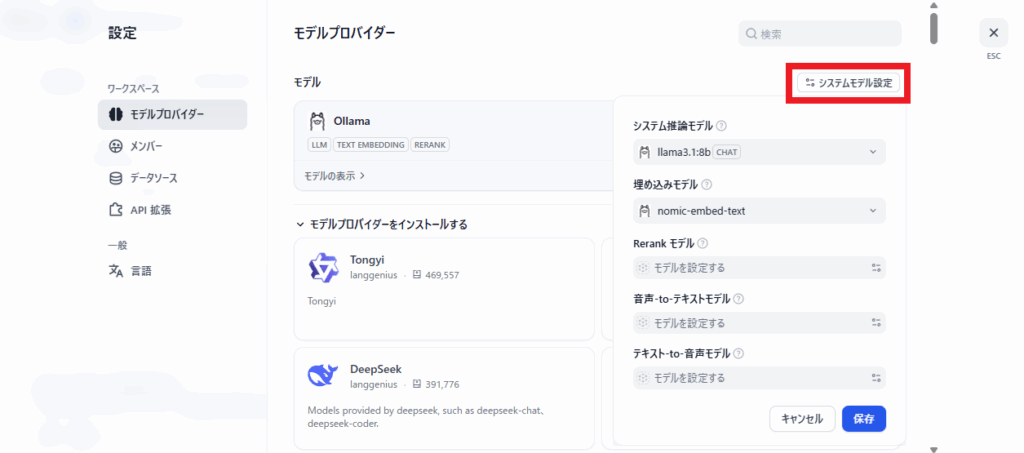
その場合、「システムモデル設定」ボタンを押して、以下を選択します(画像2. 参照)。
-
システム推論モデル:
llama3.1:8b
この時点で、チャット系機能は使えるようになりました。
埋め込みモデル(Embedding)の設定
文書を読み込ませてRAGにしたい場合、LLMだけでは足りず、埋め込みモデルが必要になります。
埋め込みモデルを追加
Ollamaに埋め込みモデルを追加します。開いているWindows PowerShellで、以下のコマンドを実行します。
- ollama pull nomic-embed-text
㊟ コマンドはどのフォルダで実行しても大丈夫です
C:\docker\dify_2026_02\dify\dockerにいても大丈夫
そうしたら、以下のコマンドで、nomic-embed-text がでればOKです。
- ollama list
Ollamaに埋め込みモデルを追加
再度、「モデルを追加」ボタンをクリックします(画像1. 参照)。
- Dify → 設定 → モデルプロバイダー → モデル:Ollama → 「モデルを追加」
LLMモデルを追加したときと同様に、各種設定をします。
-
Model Type:
Text Embedding -
Base URL:
http://host.docker.internal:12000 -
Model name:
nomic-embed-text -
認証名(任意):例
ollama-embed-12000
設定後、「保存」ボタンをクリックして、保存します。
保存後、システムモデル設定に戻ると、埋め込みモデルの選択肢に nomic-embed-text がでるようになります。
システムモデル設定で埋め込みモデルを指定
システムモデル設定で、埋め込みモデルを指定します(画像2. 参照)
-
埋め込みモデル:
nomic-embed-text
※ Rerank / 音声系モデルは未設定でもOK(後回し可能)
ここまでで、ローカル版DifyにOllamaを登録することができました。



